1. Redis集群原理-分片
在 Redis 集群环境中,通过数据分片 技术,当某个 key 需要存储或查询时,会使用分片算法 计算出 key的哈希槽编号,然后根据编号找到实际的物理节点。
2. 数据分片
数据分片(Data Sharding)技术,通过将数据分散存储到多个物理节点上,来减轻单一节点的负载压力,避免单点故障,同时也提高了整个系统的性能和容错能力,以及安全性和可靠性。
数据的分片策略包含以下两个重要概念:
- 分片键 :用来决定将数据分配到哪个分片的关键字段或属性
- 分片算法 :根据分片键来决定数据分布的具体计算方法,常见的有取模算法、范围分片、一致性哈希算法等
常用的分片算法有:
- 哈希取模分片算法 :通过对哈希值进行取模,将余数映射到不同的分片节点上
- 一致性哈希分片算法 :数据和节点都映射到一个环形空间上
- 范围分片算法 :根据数据的范围将数据分配到不同的分片节点上,例如创建时间
2.1 哈希取模
哈希算法 是一种将任意长度的输入,通过某种特定的压缩映射转换为固定长度的输出的函数。例如,岁字符串、文件等进行哈希函数后,可以得到一个较短的、固定大小的值,称为哈希值或哈希码。哈希算法也叫摘要算法、散列算法、散列函数、哈希函数。
常见的哈希算法有:
MD5:最常用的哈希算法之一,输出为128位(16字节)的哈希值SHA(Secure Hash Algorithm):安全哈希算法,包含多个版本,例如SHA-1、SHA-256、SHA-512等CRC32(Cyclic Redundancy Check):循环冗余校验算法,返回一个32位的无符号整数
哈希算法 中不同数据的输出不同,且长度固定,可以通过对哈希值进行取模运算,得到的余数作为分片的节点编号,这就是哈希取模分片算法 。
假设 Redis 基于哈希取模来实现分片的话,示意图如下:
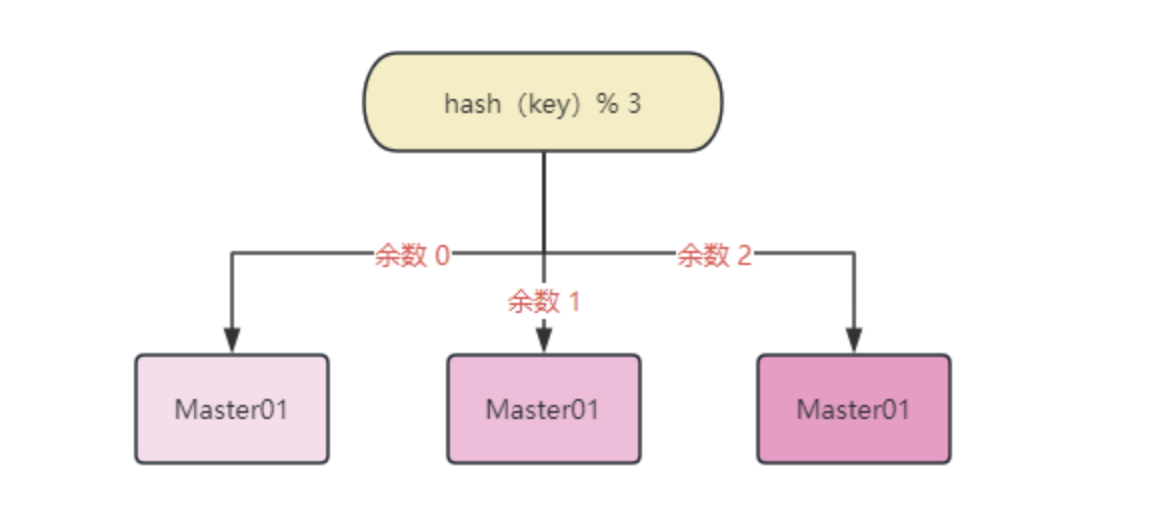
整个执行流程如下:
- 确定集群节点数
M,部署节点,确定节点编号为0 - (M -1) - 使用哈希函数对键(
key)进行哈希计算,得到哈希 - 将哈希值对节点数量(
M)进行取模运算,即hash(key) % M,计算结果K作为节点编号 - 根据节点编号找到对应的集群节点
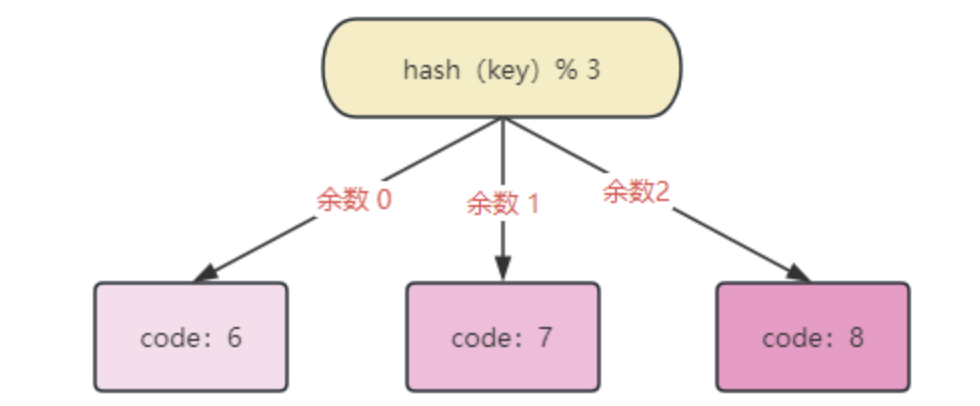
哈希取模分片算法最大的问题就是,在扩容或者缩容时,必须迁移数据,重新建立映射关系,否则会导致大范围的查询不到数据。例如,当前三个节点,存储了哈希值为 6 7 8 的三条数据:
当添加入新节点时,如果没有进行数据迁移,数据分布如下:
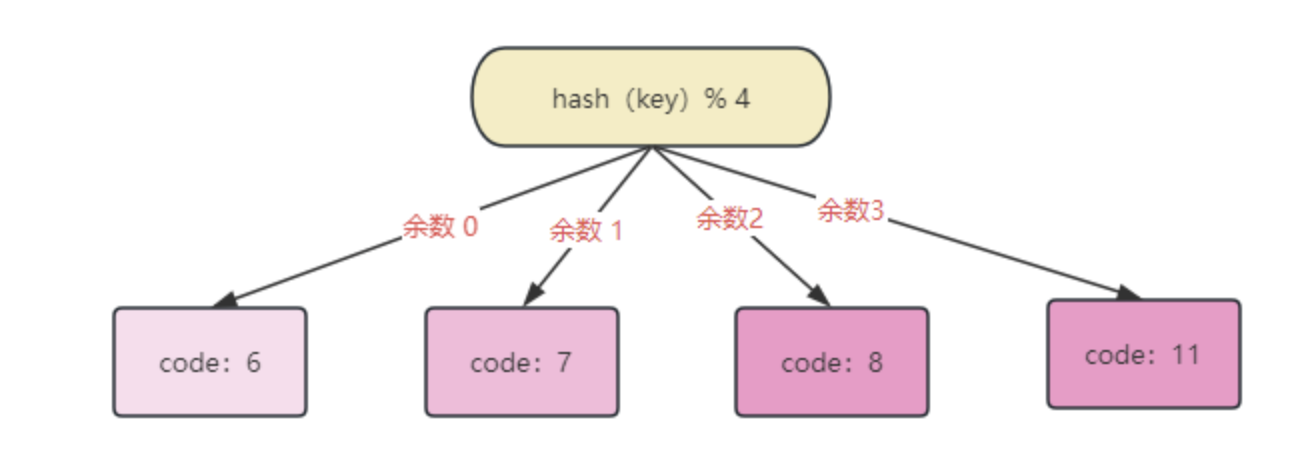
查询哈希值为 6 的数据时,% 4 的结果为2,执行到第三个节点,但是实际存储在第一个节点,所有查询不到数据。以此类推,除了新节点的数据,之前三个节点时存储的数据,现在都查询不到了。
为了解决上述问题,必须进行数据迁移,针对每条数据,使用新的分片算法迁移到新的节点。如果数据和分片节点很多,数据迁移将是一个非常大的工作量,并且迁移期间,集群是不可用的。
2.2 一致性哈希
一致性哈希算法 将数据和节点映射到一个虚拟的环形哈希空间上。由麻省理工学院的 David Karger 等人在 1997年提出,目的是解决分布式系统在扩容或者缩容时,尽可能少地影响已有的映射关系,减少数据迁移,从而保持系统的稳定性和负载均衡性。常用于分布式缓存、分布式数据库、负载均衡器。
2.2.1 哈希环
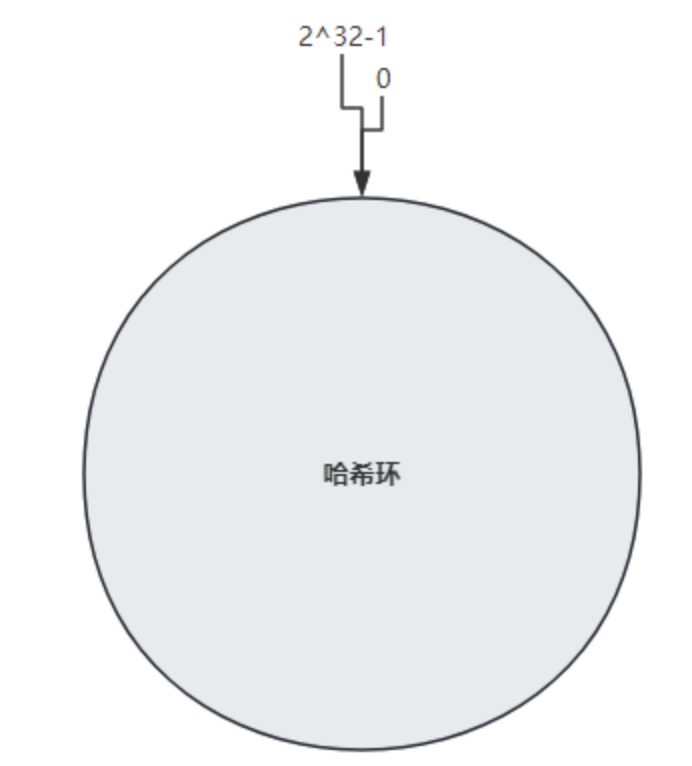
一致性哈希算法 是一种特殊的哈希取模,上面介绍的是使用哈希值对节点数量进行取模,一致性哈希则是对一个固定值( 2^32)进行取模,其取模运算结果的范围是 0 到 2^32-1(42亿多)。可以将结果全量集,进行收尾相连,在逻辑上形成一个环形空间。
整个空间按顺时针方向组织,圆环的正上方的点代表 0 ,0 点右侧的第一个点代表 1,以此类推,2、3、4、……直到2^32-1。 0 点左侧的第一个点代表 2^32-1, 0 和 2^32-1在零点方向重合,我们把这个由 2^32 个点组成的圆环称为哈希环。
哈希环示意图如下:
2.2.2 节点映射
有了哈希环之后,需要将集群中的所有节点映射到哈希环上的某一个位置。首先将服务器的某个唯一属性进行哈希运算,比如服务器的 IP或主机名,计算出来的哈希值就是该节点在哈希环上的位置,这样就建立了集群节点和哈希环的映射关系。
假如三个节点A、B、C,经过 IP 地址的哈希函数计算后,在哈希环的位置如下:
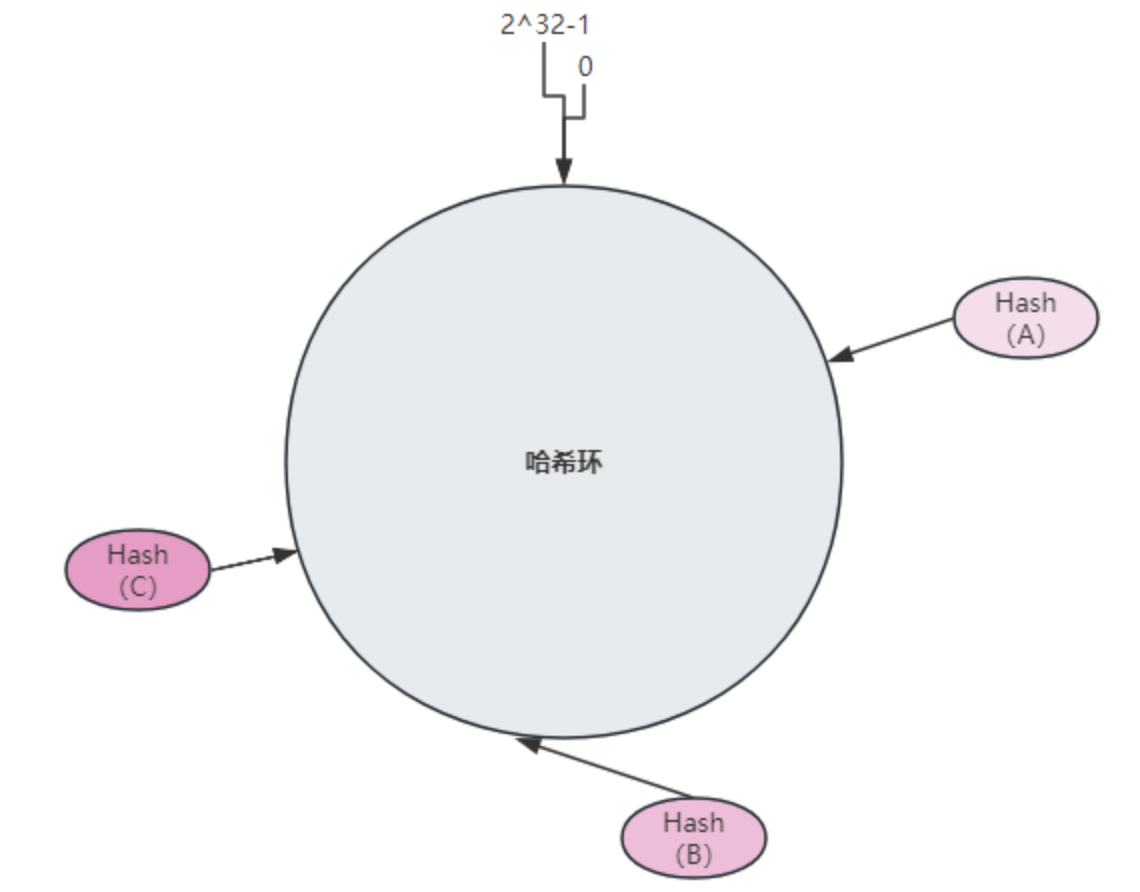
2.2.3 数据映射
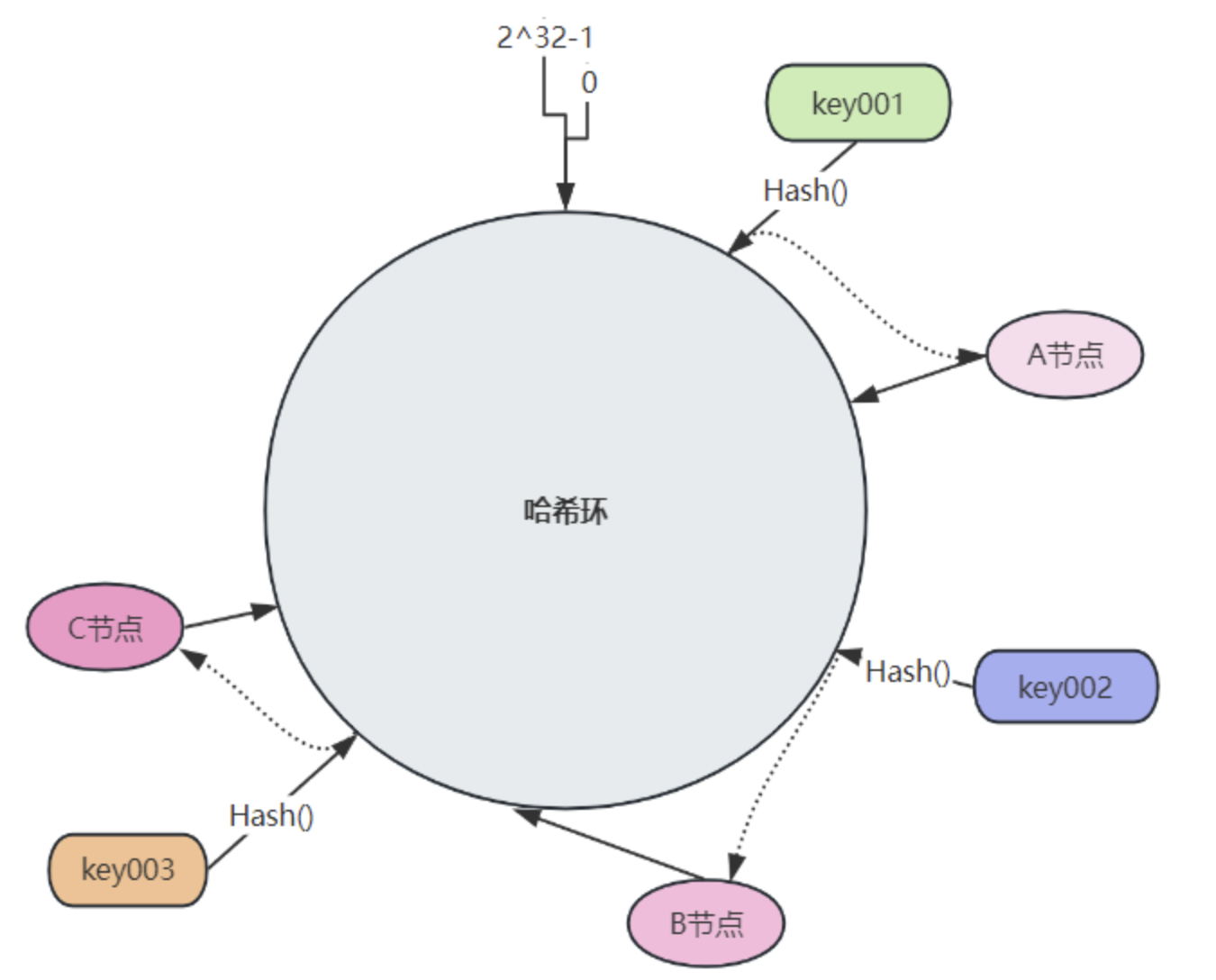
节点映射之后,需要将数据也映射到哈希环上的某一个位置,并找到相应的数据节点。假设 Redis 基于一致性哈希来实现分片的话,当需要存储或访问某个 key 时,首先计算哈希值并取模,计算结果就是 key在哈希环上的位置。然后,沿着哈希环的顺时针方向查找第一个遇到的节点,该节点即为数据的存储或访问节点。
假设有 key001、 key002、 key003 三条数据, key001 将被路由到节点 A, key002 将被路由到节点B, key003 将被路由到节点 C:
2.2.4 优缺点
当某个节点宕机时,只会影响到该节点和前一个节点的数据,但是其他位置的数据并不影响。例如,当 B 宕机时,原先A 和 B 之间的 key会被路由到 C 节点(未宕机是 B ):
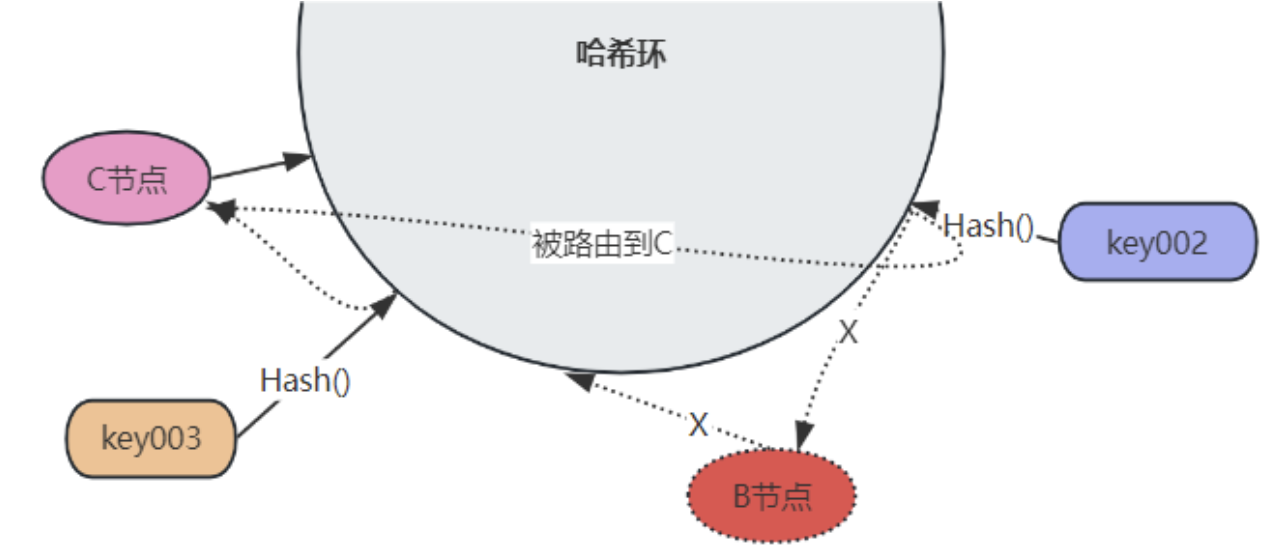
D 时,只需要将 C 和 D 之间的 key 重新映射到 D 即可,不需要针对所有数据进行迁移:
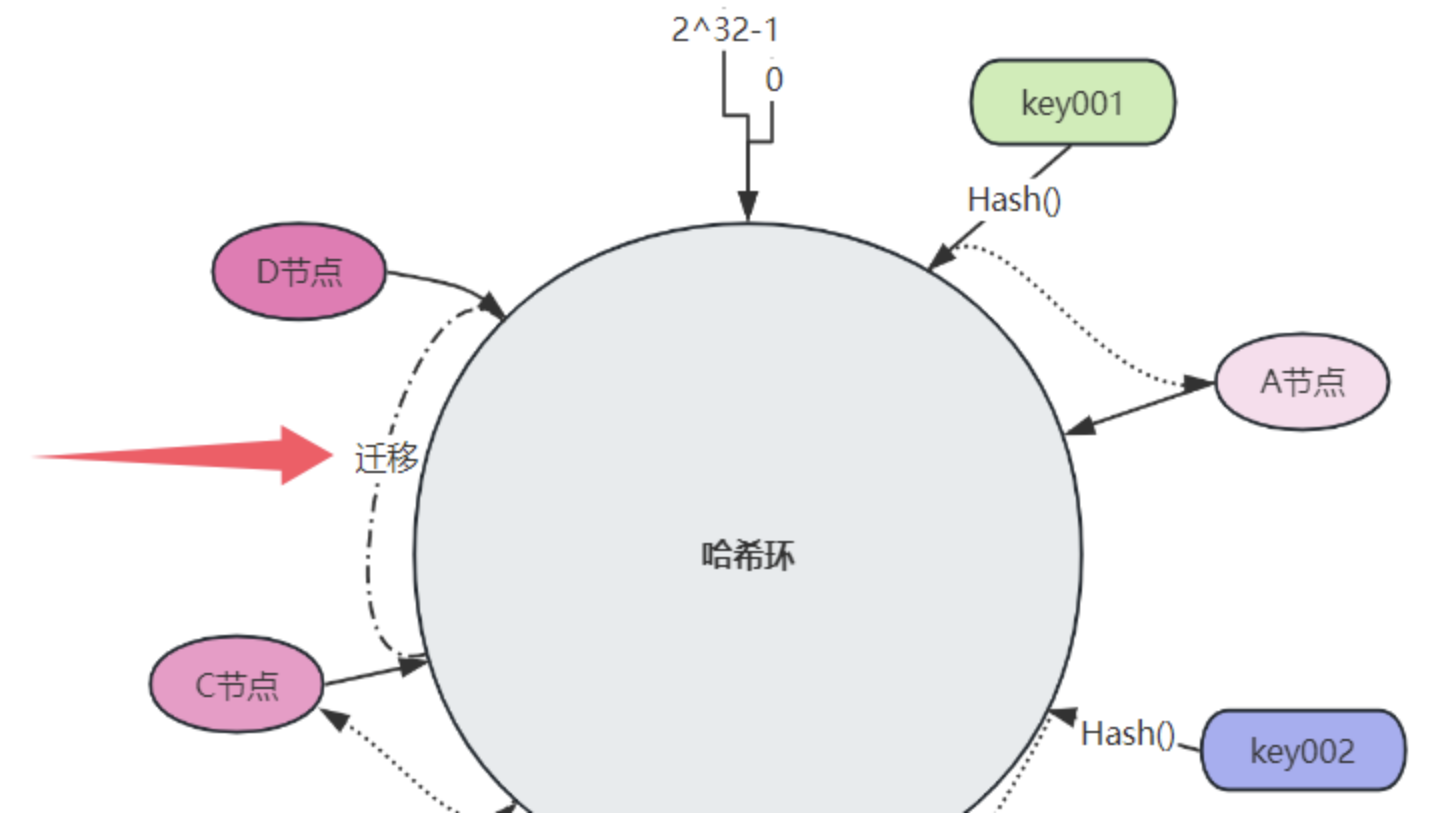
一致性哈希存在数据数据倾斜问题,当服务节点太少时,容易因为节点分布不均匀,导致大量数据被缓存到某一台或某几台服务器上,而其他服务器上的数据则相对较少。数据倾斜会导致某些服务器承受过高的访问压力,其性能可能会受到影响,甚至可能导致服务中断,进而影响整个系统的稳定性。
例如,下图中,只有两个节点,D - A之间分配的哈希环位置明显偏小,势必会造成 D 节点存储的数据远超过 A 节点:
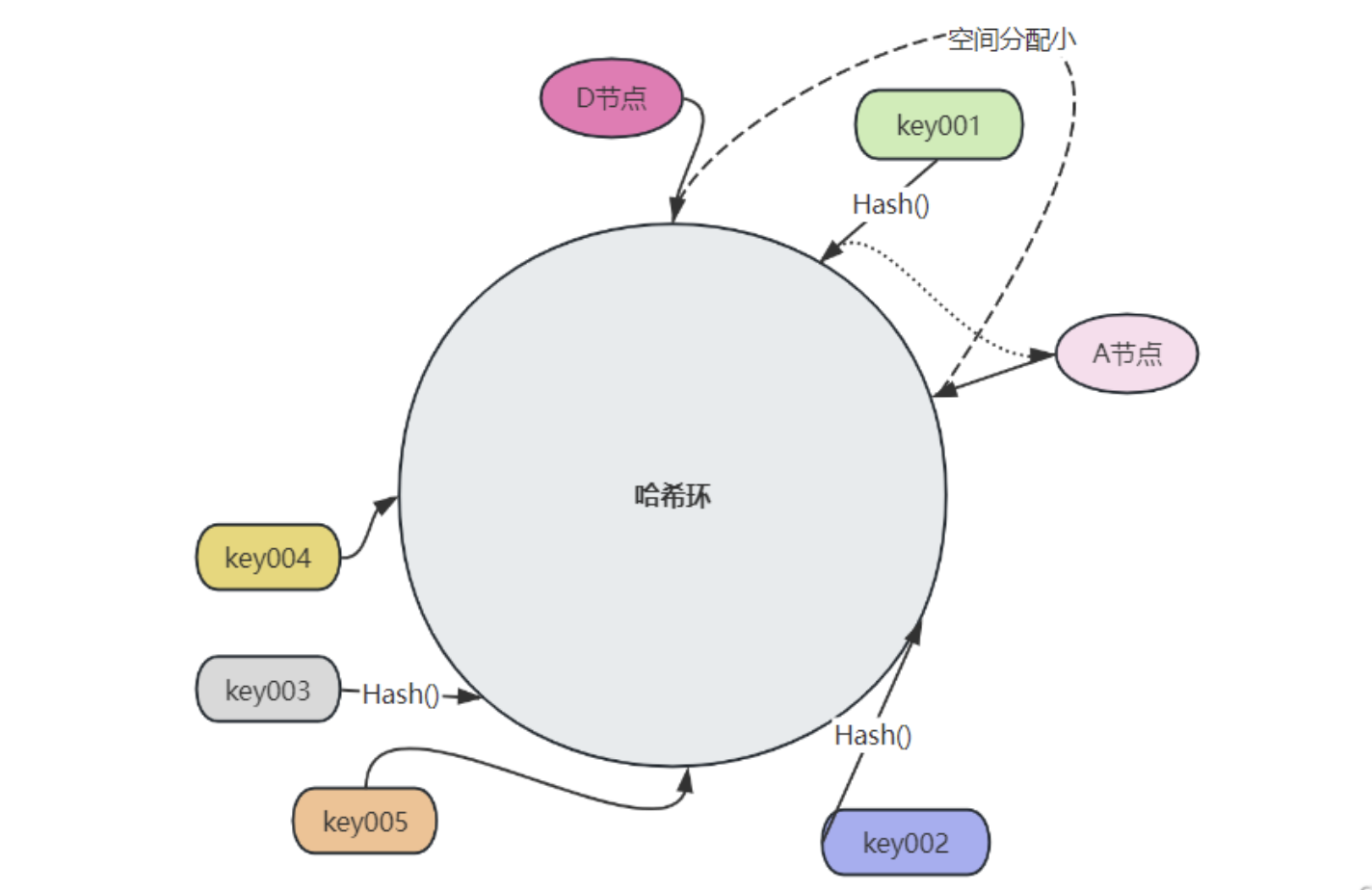
2.3 哈希槽
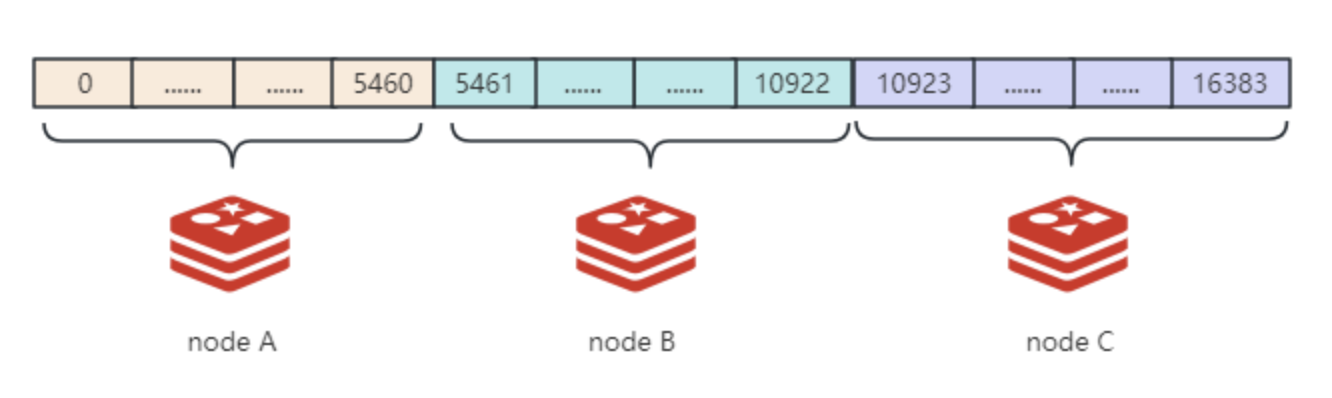
Redis 在哈希取模和一致性哈希的基础上,实现了自己的数据分片策略。 Redis 也是对一个固定值( 2^14)进行取模,其取模运算结果的范围是 0 到 2^14-1(16384)。 Redis 将所有可能的键空间分为 16384个哈希槽(Hash Slot),每个槽可以存储一个或多个键值对。
集群中的每个主节点,都会均匀分配哈希槽:
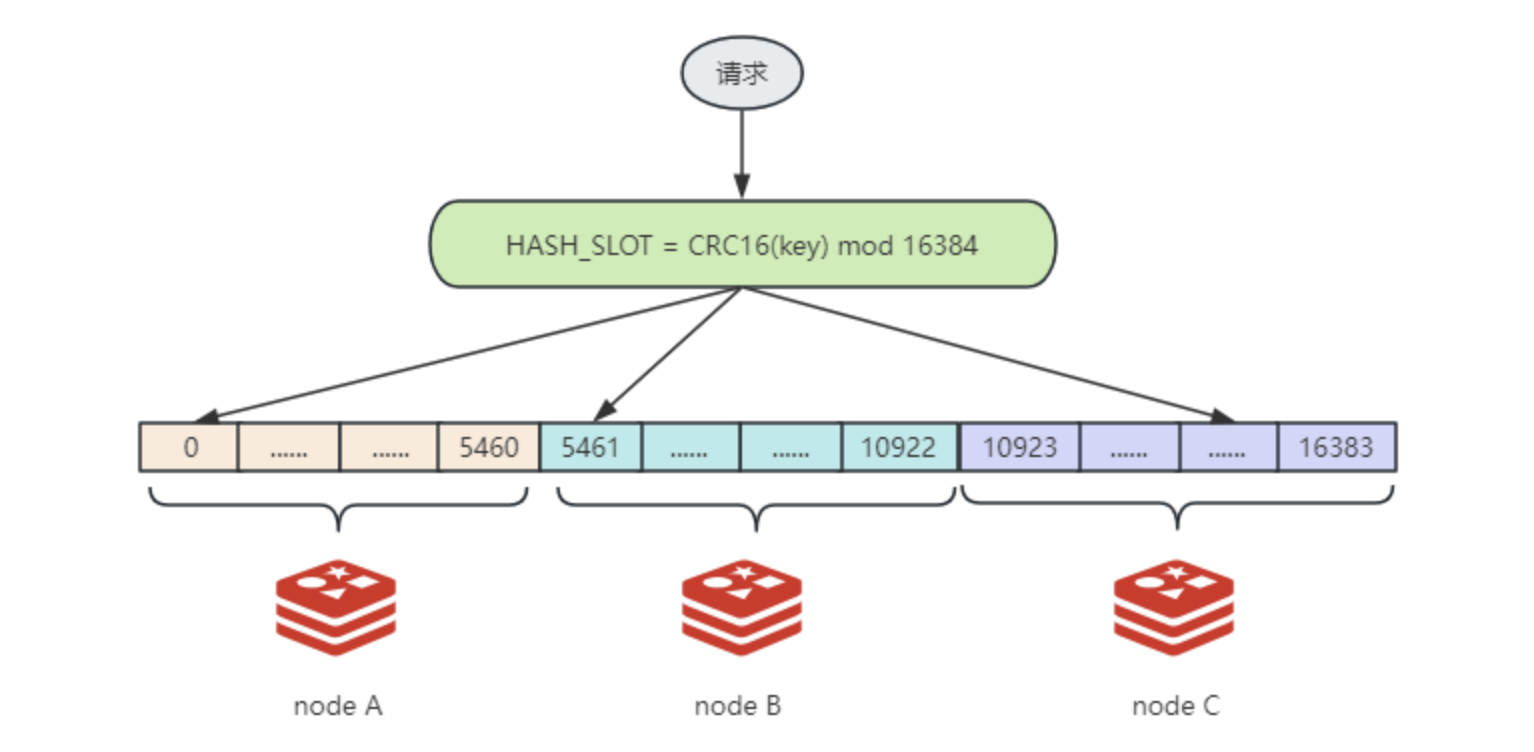
当存储或者查询 key 时,先使用 CRC16 循环冗余校验算法计算出 Key 的校验码,然后对计算结果使用 16384进行取模计算,其结果为 0 - 16383 之间的整数,计算结果称为哈希槽编号,公式如下:
HASH_SLOT = CRC16(key) mod 16384
例如,使用 lettuce 计算出 key001 、key002 的哈希槽分别为 12657 、 274 :
// lettuce
int key001 = SlotHash.getSlot("key001");
int key002 = SlotHash.getSlot("key002");
System.out.println(key001); // 12657
System.out.println(key002); // 274
然后根据哈希槽编号找到实际的物理节点, key001 路由到 C 节点,key002 路由到 A 节点,整个过程示意图如下:
哈希槽能够将数据均匀地分布在多个节点上,相较于一致性哈希,解决了数据倾斜问题。当需要添加或移除节点时,Redis集群可以利用哈希槽信息动态地重新分配数据,而不需要重新分片整个数据集,这样可以避免大规模的数据迁移。