限流算法之计数器算法
1.简介
在现代的业务应用系统中,由于负载能力有限,我们经常需要面对大流量时的流量控制问题。服务接口的流量控制策略包括分流、降级和限流等。
2.限流场景
限流策略的目的是为了防止非预期的请求对系统压力过大,从而拖垮业务应用系统。常见的限流场景包括:
- Nginx前端层面限流:通过IP、账号等规则在Nginx层面进行限流。
- 业务应用系统层面限流:包括客户端和服务器端的限流。
- 数据库层面限流:确保数据库的稳定运行。
3.计数器算法
计数器算法是最简单的限流算法。例如,对于一个接口,我们可以规定1分钟内的访问次数不能超过100次。实现这个算法,我们可以设置一个计数器counter,每当有请求过来时,counter就加1。如果counter的值超过了限制且请求间隔在1分钟内,就拒绝请求;否则,如果请求间隔超过1分钟且counter在限制范围内,就重置counter。
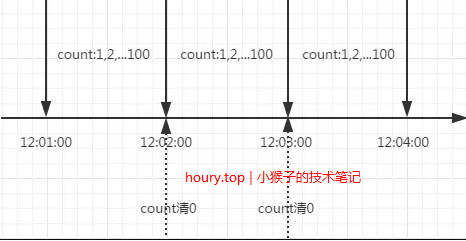
3.1 使用AtomicLong
package top.houry.limit;
import java.security.SecureRandom;
import java.util.Random;
import java.util.concurrent.ExecutorService;
import java.util.concurrent.Executors;
import java.util.concurrent.atomic.AtomicLong;
import java.util.stream.IntStream;
public class CountRateLimiter {
private AtomicLong counter = new AtomicLong(0);
private static long timestamp = System.currentTimeMillis();
private long limit;
public CountRateLimiter(long limit) {
this.limit = limit;
}
public boolean tryAcquire() {
long now = System.currentTimeMillis();
if (now - timestamp < 1000) {
if (counter.get() < limit) {
counter.incrementAndGet();
return true;
} else {
return false;
}
} else {
counter = new AtomicLong(0);
timestamp = now;
return false;
}
}
public static void main(String[] args) {
CountRateLimiter rateLimiter = new CountRateLimiter(100);
IntStream.range(0,2000).forEach(v ->{
boolean result = rateLimiter.tryAcquire();
System.out.println("请求 " + v + ": " + (result ? "通过" : "拒绝"));
try {
// 模拟请求间隔 (可以先注释掉,然后再试放开,观察2次效果)
Thread.sleep(10);
} catch (InterruptedException e) {
e.printStackTrace();
}
});
}
}
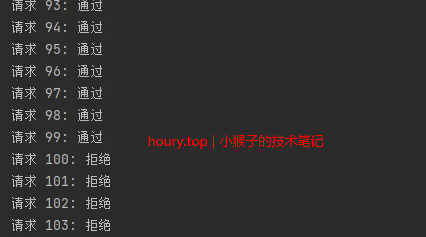
运行结果:
3.2 使用Guava Cache
使用Guava的Cache来存储计数器,设置过期时间为1秒,然后以当前时间戳的秒数作为KEY进行计数统计和限流需要提前在maven中引入Guava的依赖:
<dependency>
<groupId>com.google.guava</groupId>
<artifactId>guava</artifactId>
<version>31.1-jre</version>
</dependency>
package top.houry.limit;
import com.google.common.cache.CacheBuilder;
import com.google.common.cache.CacheLoader;
import com.google.common.cache.LoadingCache;
import java.util.concurrent.ExecutionException;
import java.util.concurrent.TimeUnit;
import java.util.concurrent.atomic.AtomicLong;
public class GuavaRateLimiter {
private final LoadingCache<Long, AtomicLong> cache;
public GuavaRateLimiter() {
this.cache = CacheBuilder.newBuilder()
.expireAfterWrite(1, TimeUnit.SECONDS) // 每个键的有效期为1秒
.build(new CacheLoader<Long, AtomicLong>() {
@Override
public AtomicLong load(Long key) {
return new AtomicLong(0);
}
});
}
public boolean tryAcquire() throws ExecutionException {
long now = System.currentTimeMillis() / 1000; // 当前时间秒数
try {
AtomicLong count = cache.get(now);
return count.incrementAndGet() <= 100;
} catch (ExecutionException e) {
// 如果加载过程中出现异常,重新尝试获取缓存
return cache.get(System.currentTimeMillis() / 1000).incrementAndGet() <= 100;
}
}
public static void main(String[] args) {
GuavaRateLimiter rateLimiter = new GuavaRateLimiter();
try {
for (int i = 0; i < 150; i++) {
boolean result = rateLimiter.tryAcquire();
System.out.println("请求 " + i + ": " + (result ? "通过" : "拒绝"));
// Thread.sleep(10); // 模拟请求间隔
}
} catch (Exception e) {
e.printStackTrace();
}
}
}
运行结果:
